시퀸스-투-시퀸스(Sequence-to-Sequence) 모델
리커런트 뉴럴 네트워크는 RNN 튜토리얼에서 이미 이야기 했던것 처럼 언어를 모델화하는 것을 학습할 수 있다.
(그것을 읽지 않았다면, 이 튜토리얼을 읽기전에 그것을 먼저 읽기를 권한다). 흥미로운 질문이 있다: 몇몇의 입력으로 생성된 단어들을 조건화 할수 있고 어떤 의미있는 응답을 생성할수 있을까? 예를 들어, 영어를 프랑스어로 번역하기 위한 뉴럴 네트워크를 학습할수 있을까? 답은 예가 된다.
이 튜토리얼은 그런 앤드-투-앤드 (end-to-end)시스템을 만들고 학습하는 방법 보여줄 것이다. pip를 통해 tensorflow를 이미 설치했고 tensorflow git 저장소를 클론(clone)했고, git tree의 root에 있다고 가정한다.
그리고 나서, 번역 프로그램을 실행함으로 시작할수 있다:
cd tensorflow/models/rnn/translate
python translate.py --data_dir [your_data_directory]
그 프로그램은 WMT'15 웹사이트에서 영어-프랑스어 번역 데이타를 다운받을 것이고 학습을 준비하고 학습할 것이다. 그 데이타는 20GB 공간을 차지할 것이고, 다운로드하고 준비하기 위해 좀 시간이 걸린다(상세히 알고 싶으면 나중에 보라). 그래서 이 튜토리얼을 읽는 동안 프로그램을 구동시키고 실행해 두자.
이 튜토리얼은 models/rnn에서 아래 파일을 참고한다.
| 파일 | 그 안에 무엇이 있나 |
|---|---|
seq2seq.py |
시퀸스-투-시퀸스 모델을 생성하기 위한 라이브러리. |
translate/seq2seq_model.py |
뉴럴 번역 시퀸스-투-시퀸스 모델. |
translate/data_utils.py |
번역 데이타를 준비하기 위한 도움 함수들. |
translate/translate.py |
번역 모델을 훈련하고 실행시키는 바이너리(binary). |
기본적인 시퀸스-투-시퀸스(Sequence-to-Sequence)
Cho et al., 2014 (pdf)에서 소개된 기본적인 시퀸스-투-시퀸스 모델은 두개의 리커런트 뉴럴 네트워크(RNN)으로 구성된다: 입력을 처리하는 인코더와 결과를 생성하는 디코더. 이 기본 구조는 아래와 같이 묘사된다.

위 그림에 각 박스는 가장 일반적으로 GRU 쎌이거나 LSTM 쎌인 RNN 쎌을 나타낸다(RNN Tutorial를 참조하길 바란다). 인코더와 디코더는 가중치를 공유 할수 있거나, 더 일반적으로는 다른 매개변수 집합을 사용한다. 다중층 쎌들은 역시 시퀸스-투-시퀸스에서 성공적으로 사용되어 왔다. 예로 번역 Sutskever et al., 2014 (pdf)에서 알수 있다.
위에서 설명된 기본 모델에서, 모든 입력은 디코더에 전달되는 유일한 것이기 때문에 고정된 크기를 가진 상태 벡터로 인코딩 되어져야 한다. 디코더가 입력에 더 직접적인 접근을 가능케 하기 위해, 주의(attention) 메카니즘이 Bahdanau et al., 2014(pdf)에서 소개된다. 주의(attention) 메카나즘에 대해서 상세히 보지 않을 것이다(논문을 참고), 그것은 디코더가 모든 디코딩 단계에서 입력을 엿보게 해주는 것이라고 언급하는 것만으로도 충분하다. LSTM 쎌을 가진 여러층의 시퀸스-투-시퀸스 네트워크와 디코더 안에 어탠션 메카니즘은 이처럼 보인다.
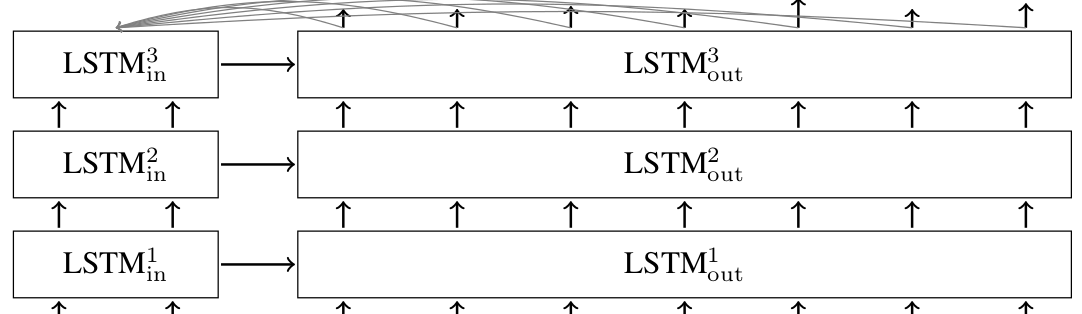
텐서플로우(TensorFlow) seq2seq 라이브러리
위에서 볼수 있듯이, 다른 많은 시퀸스-투-시퀸스 모델들이 있다. 각각 이러한 모델은 다른 RNN 쎌들을 사용할 수 있다, 그러나 모두 인코더 입력과 디코디 입력을 받아야 한다. 이것은 텐스플로우 seq2seq 라이브러리(models/rnn/seq2seq.py)의 인터페이스에 동기를 준다.
기본적인 RNN 인코더-디코더 시퀸스-투-시퀸스 모델은 아래처럼 동작한다.
outputs, states = basic_rnn_seq2seq(encoder_inputs, decoder_inputs, cell)
위에 호출에서, encoder_inputs는 인코더에 입력을 나타내는 텐서(tensor) 리스트이다. 예로, 위에 첫번째 그림에서 문자 A, B, C에 해당된다. 유사하게, decoder_inputs는 디코더에 입력을 나타내는 텐서들이다. 첫번째 그림에 GO, W, X, Y, Z 이다.
cell 인수는 models.rnn.rnn_cell.RNNCell클래스의 인스턴스이다, 그것은 어느 쎌이 그 모델 안에서 사용할지를 결정한다. 예를 들어 GRUCell 또는 LSTMCell, 또는 자신의 것을 작성할 수 있다.
게다가, rnn_cell은 여러층 쎌을 만들고, 쎌 입력과 결과에 드랍아웃(dropout)를 추가하거나 다른 변환을 하기 위한 랩퍼(wrapper)들을 제공한다. 예제들을 보기 위해서는RNN Tutorial를 참고 하기 바란다.
basic_rnn_seq2seq 호출은 두개의 인수를 리턴한다: outputs 와 states. 그것 둘다 decoder_inputs와 동일한 크기의 탠서 리스트이다. 자연스럽게, outputs는 각 시간 단계(time-step)에서 디코더 결과에 해당된다, 위 첫번째 그림에서 그것은 W, X, Y, Z, EOS가 된다. 반환된 states는 모든 시간 단계에서 디코더의 내부 상태를 나타낸다.
시퀸스-투-시퀸스 모델의 많은 애플리케이션에서, 시간 t에 디코더 결과는 다시 시간 t+1에 디코더의 입력으로 전달된다. 테스트 시간에, 어떤 시퀸스를 디코딩할때, 이것은 그 시퀸스가 만들어지는 방법이다. 반면에, 학습동안 디코더가 전에 실수를 했어도 모든 시간 단계에 디코더에 올바른 입력을 제공하는 것이 일반적이다. seq2seq.py에 함수들은 feed_previous 인수를 사용해서 두가지 모드를 지원한다. 예를 들어, 아래에 임베드 RNN모델 사용을 분석해 보자.
outputs, states = embedding_rnn_seq2seq(
encoder_inputs, decoder_inputs, cell,
num_encoder_symbols, num_decoder_symbols,
output_projection=None, feed_previous=False)
embedding_rnn_seq2seq모드에서, 모든 입력들은(encoder_inputs 과 decoder_inputs) 이산 값(discrete value)을 나타내는 정수-텐서(integer-tensor)들이다. 그것들은 조밀한(dense) 표현으로 임베딩되어 질 것이다(임베딩에 대해 더 자세한 설명을 위해 Vectors Representations Tutorial 를 보길 권한다, 그러나 이러한 임베딩을 만들기 위해서 나타나는 이산 심볼의 최대 수를 지정할 필요가 있다: 인코더 쪽에 num_encoder_symbols, 그리고 디코더 쪽에 num_decoder_symbols.
위 호출에서, feed_previous를 False로 설정했다. 이것은 디코더에 전달되는 decoder_inputs를 사용할 것이다. feed_previous가 True로 설정되면, 디코더는 decoder_inputs의 단지 첫번째 원소만 사용할 것이다. 이 리스트에 모든 다른 텐서들은 무시 되어지고, 그대신 디코더의 이전 결과가 사용되어 질 것이다. 이것은 우리의 번역 모델에서 번역을 디코딩 하기 위해서 사용되어진다. Bengio et al., 2015
(pdf)와 유사하게 그 모델이 그 자신의 실수에 더 견고하기 하기 위해 또한 학습동안에도 사용되어 질수 있다.
위에서 사용된 더 중요한 한 인수는 output_projection이다. 그것이 명시되지 않는다면, 임베딩 모델의 결과는 각 생성된 심볼에 대해 로짓(logit)들로 나타내기 때문에 배치사이즈 x num_decoder_symbols의 형태를 가진 텐서가 될 것이다. 아주 큰 사전을 가지고 모델을 학습할때, 예를 들어, num_decoder_symbols이 아주 클때, 아주 큰 이러한 탠서들을 저장하는것은 비실용적이다. 그대신, 좀더 작은 결과 텐서를 리턴하는 것이 좋다. 그 텐서는 나중에 output_projection를 사용해서 큰 결과 텐서에 투여되어진다. 이것은 Jean et. al., 2014
(pdf)에서 설명하는 대로 샘플 소프트맥스 로스(sampled softmax loss)를 가진 seq2seq모델을 사용할수 있게 해준다.
basic_run_seq2seq와 embedding_rnn_seq2seq에 더해서, seq2seq.py에 좀더 많은 시퀸스-투-시퀸스 모델들이 있고, 그것을 볼 것이다. 그것들은 유사한 인터페이스를 가진다, 그래서 상세히 설명하지는 않을 것이다. 아래에 우리의 번역 모델을 위해 embedding_attention_seq2seq를 사용할 것이다.
뉴럴 번역 모델(Neural Translation Model)
시퀸스-투-시퀸스(sequence-to-sequence) 모델의 중요한 부분은 models/rnn/seq2seq.py에 있는 함수에 의해 구성되어지지만, 여전히 models/rnn/translate/seq2seq_model.py안에 우리 번역 모델에서 사용되어지고 언급할 가치가 있는 몇가지 기교가 있다.
샘플 소프트맥스와 결과 프로젝션(Sampled softmax and output projection)
하나는, 위에서 이미 언급한 대로, 우리는 아주 큰 사전을 다루기 위해서 샘플 소프트맥스(sampled softmax)를 사용하길 원한다. 그것으로 부터 디코딩하기 위해 결과 프로젝션(output projection)를 기억할 필요가 있다. 샘플 소프트맥스 로스(loss)와 결과 프로젝트 둘다는 seq2seq_model.py에 있는 다음 코드에 의해 구성되어진다.
if num_samples > 0 and num_samples < self.target_vocab_size:
w = tf.get_variable("proj_w", [size, self.target_vocab_size])
w_t = tf.transpose(w)
b = tf.get_variable("proj_b", [self.target_vocab_size])
output_projection = (w, b)
def sampled_loss(inputs, labels):
labels = tf.reshape(labels, [-1, 1])
return tf.nn.sampled_softmax_loss(w_t, b, inputs, labels, num_samples,
self.target_vocab_size)
우선, 샘플 수(디폴트가 512)가 목적(target) 사전 크기보다 작다면, 단지 샘플 소프트맥스를 구성한다는 것을 기억하자. 512보다 작은 사전에 대해, 그냥 표준 소프트맥스 손실(softmax loss)를 사용하는 것이 더 나은 생각일지도 모른다.
if output_projection is not None:
self.outputs[b] = [tf.matmul(output, output_projection[0]) +
output_projection[1] for ...]
그리고 나서, 알다시피, 우리는 결과 프로젝트를 구성한다. 그것은 가중치 행렬과 바이어스(bias) 벡터로 구성된 순서쌍이 된다. 그것이 사용되어지면, rnn쎌은 배치크기 xtarget_vocab_size가 아니라 배치 크기xsize의 벡터들이 리턴될 것이다. 로짓(logit)를 복구하기 위해, seq2seq_model.py에 124-126라인에서 했던 것처럼 가중치 행렬에 의해서 곱해지고, 바이어스가 더해질 필요가 있다.
버켓팅(Bucketing)과 패딩(padding)
샘플 소프트맥스에 더해서, 우리의 번역 모델은 또한 버켓팅(bucketing)를 사용한다, 그것은 다른 크기의 문장을 효과적으로 다루기 위한 방법이다. 우선 그 문제를 명확히 해 보자. 영어에서 프랑스어로 번역할때, 입력으로 L1 크기의 영어문장과 결과로 L2 크기의 프랑스 문장이 있을 것이다. 영어 문장이 encoder_inputs으로 전달되고 프랑스어 문장은 decoder_inputs(GO 심볼이 앞에 붙혀진다) 로 나오기 때문에, 기본적으로 (L1, L2+1)의 모든 순서쌍에 대해 seq2seq 모델을 만들어야 한다. 이것은 아주 유사한 서브 그래프들로 구성되는 거대한 그래프를 만들게 될 것이다. 다른한편으로 특별한 PAD 심볼을 가지고 모든 문장에 간단히 메워 넣을 수 있다. 그러면, 우리는 메워진 크기에 대한 단지 하나의 seq2seq 모델만 만들 필요있게 된다. 그러나 문장이 더 짧을 수록 쓸모없는 PAD 심볼에 대해 디코딩 인코딩 해야되기 때문애 우리의 모델은 비효율적이게 된다.
모든 길이의 순서쌍에 대해 그래프를 생성하는 것과 하나의 길이로 패딩하는 것 사이에 절충으로써 몇개의 버켓(bucket)를 사용하고 각 문장을 그 위에서 있는 버켓의 길이로 메워 넣는다.translate.py에서 다음과 같은 기본적인 버켓들을 사용한다.
buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
이것은 3개의 토근을 가진 영어 문장이 입력이고 6개의 토근을 가진 프랑스어 문장이 그 입력에 대한 결과라고 한다면 그것들은 첫번째 버켓에 들어가게 되고 인코더 입력에 길이 5까지 메워넣고, 디코더 입력에 대해서는 길이 10까지 메워넣게 된다. 8개의 토근을 가진 영어문장이고 그에 상응하는 프랑스어 문장이 18개의 토근을 가진다면, 버켓 (10, 15)에 맞지 않고, 버켓 (20, 25)이 사용될 것이다. 예를 들어, 그 영어 문장은 길이 20까지 메워 질것이고, 프랑스어 문장은 길이 25까지 메워진다.
디코더 입력을 만들때, 특별한 GO심볼을 입력 데이타 앞에 붙히는 것을 기억하자. 이것은 seq2seq_model.py에 get_batch()함수 안에서 이루어진다. 그것은 또한 영어 문장 입력을 반대로 변환한다. 입력을 반대로 변환하는 것은 Sutskever et al., 2014
(pdf)에서 뉴럴 번역 모델에 대한 결과를 향상시키는 것을 보여주었다. 이것 모든 것을 다 넣기 위해, "I go." 라는 문장이 있다고 가정하고, 입력으로 ["I", "go", "."]로 토근화 되고 결과로 "Je vais"가 되고 ["Je", "vais", "."]로 토근화 된다. 그것은 [PAD PAD "." "go" "I"]로 인코더 입력이고, [GO "Je" "vais" "." EOS PAD PAD PAD PAD PAD]는 디코더 입력으로 버켓 (5,10)에 들어가게 될것이다.
그것을 실행해보자
위에 설명되어진 대로 모델을 훈련하기 위해, 우리는 아주 큰 영어-프랑스어 코퍼서(corpus)가 필요하다. WMT'15 Website에서 10^9-French-English corpus를 훈련을 위해 사용할 것이고, 개발 셋(development set)으로 그 동일한 사이트에서 2013 news test를 사용할 것이다.
python translate.py
--data_dir [your_data_directory] --train_dir [checkpoints_directory]
--en_vocab_size=40000 --fr_vocab_size=40000
약 18GB 디스크 공간을 차지 하고 훈련 코퍼스를 준비하기 위해 몇 시간이 걸린다. 그것이 풀려지면, 사전 파일들이 data_dir에 만들어 진다, 그리고 나서 그 코퍼스는 토근화 되어지고 정수 식별자(integer id)로 변환될것이다. 사전 크기를 결정하는 매개변수들을 주시하자. 위 예에서, 가장 일반적인 단어 4만개에 있는 않는 모든 단어들은 모르는 단어를 나타내는 UNK토근으로 변환 될것이다. 사전 크기를 변경한다면 바이너리는 토근 식별자(token id)를 그 코퍼스에 다시 연결 할것이다.
데이타가 준비된 뒤에, 훈련이 시작된다. translate에 있는 디폴트 매개변수는 꽤 큰 값으로 설정되어 있다. 아주 긴 시간 동안 학습된 큰 모델은 좋은 결과를 준다, 그러나 너무 긴 시간과 GPU에 너무 많은 메모리를 사용할지도 모른다. 다음 예처럼 더 작은 모델을 학습하는 것을 요청할 수 있다.
python translate.py
--data_dir [your_data_directory] --train_dir [checkpoints_directory]
--size=256 --num_layers=2 --steps_per_checkpoint=50
위 명령은 256 유닛(디폴트는 1024)을 가진 각 2개층(디폴트는 3)을 가진 모델을 학습할 것이고, 50 단계(디폴트는 200) 마다 체크포인트(checkpoint)를 저장할 것이다. 여러분의 GPU의 메모리에 얼마나 큰 모델이 맞게 할 수 있는지 알기 위해 이러한 매개변수를 통해 할수 있다.
학습 동안, 모든 steps_per_checkpoint 단계에서 바이너리는 최근 단계로 부터 통계를 프린터 할것이다. 디폴트 매개변수(크기 1024의 3개층)와 함께 첫번째 메시지는 이처럼 보인다.
global step 200 learning rate 0.5000 step-time 1.39 perplexity 1720.62
eval: bucket 0 perplexity 184.97
eval: bucket 1 perplexity 248.81
eval: bucket 2 perplexity 341.64
eval: bucket 3 perplexity 469.04
global step 400 learning rate 0.5000 step-time 1.38 perplexity 379.89
eval: bucket 0 perplexity 151.32
eval: bucket 1 perplexity 190.36
eval: bucket 2 perplexity 227.46
eval: bucket 3 perplexity 238.66
각 단계는 단지 1.4초보다 빠르게 걸린다는 것과 훈련 셋에 퍼플렉서티(perplexity)와 개발 셋에 퍼플렉서티들을 볼수 있다. 대략 3만 단계 뒤에, 짧은 문장(버켓이 0과 1)에 대한 퍼플렉서티가 한 자릿수로 된다. 훈련 코퍼스는 ~22M 문장을 포함하기 때문에, 각 epoch(훈련 데이타 전체 한번 통과)은 64의 배치크기로 대략 340K 단계가 걸린다. 이 시점에, 그 모델은 --decode 옵션을 사용해서 영어 문장에서 프랑스 문장으로 변역하기 위해 사용되어 질 수 있다.
python translate.py --decode
--data_dir [your_data_directory] --train_dir [checkpoints_directory]
Reading model parameters from /tmp/translate.ckpt-340000
> Who is the president of the United States?
Qui est le président des États-Unis ?
다음은?
위 예는 앤드-투-앤드(end-to-end)로 영어-에서-프랑스어(English-to-French) 번역기를 만드는 방법을 보여준다. 스스로 그것을 실행하고 그 모델이 어떻게 수행하는지 봐라. 그것이 꽤 괜찮은 성능을 보이지만, 디플트 매개변수로 최고의 번역 모델이 주어지지 않는다. 여기 여러분이 그것을 향상 시킬수 있는 몇가지 방법이 있다.
무엇보다, data_utils안에 basic_tokenizer인 아주 기본적인 토큰생성자를 사용한다. 더 좋은 토큰 생성자는 WMT'15 Website에서 찾을수 있다. 저 토근 생성자와 더 큰 사전을 사용하는 것은 번역을 향샹 시킬 것이다.
또한, 그 번역 모델의 디폴트 매개변수는 최적화 되지 않았다. 학습 비율(learning rate)이나 디케이(decay)를 변경하거나, 다른 방법으로 여러분의 모델의 가중치들을 초기하는 것을 시도 할수 있다. 또한 seq2seq_model.py에 있는 디폴트인 GradientDescentOptimizer를 더 혁신적인 AdagradOptimizer로 변경할 수 있다. 이러한 것들을 시도하고 결과가 어떻게 향샹 되는지 보자.
마지막으로, 위에서 나타난 모델은 번역뿐만 아니라 어떤 시퀸스-투-시퀸스 작업에 대해서도 사용되어 질수 있다. 하나의 시퀸스을 트리로 변환하기 원한다고 할지라도, 예를 들어 파싱 트리를 생성하기, 위처럼 동일한 모델은Vinyals & Kaiser et al., 2014 (pdf)에서 보여진대로 최고의 결과를 준다. 그래서 여러분 자신의 번역기를 만들수 있을 뿐만 아니라 또한 파서, 챗봇, 또는 당신 머리에 떠오르는 어떤 프로그램도 만들수 있다. 실험해보라!