TensorFlow 메커니즘 기초
코드: tensorflow/examples/tutorials/mnist/
이 튜토리얼의 목표는 TensorFlow를 사용해 어떻게 트레이닝 하는지 그리고 전형적인 MNIST 데이터 셋을 사용해 손으로 쓴 숫자를 구별하는 간단한 feed-forward neural network를 평가하는지 보여주는 것이다. 이 튜토리얼 대상 독자는 TensorFlow 사용에 관심이 있는 머신러닝 유경험자다.
이 튜토리얼은 일반적인 머신러닝 교육에 적합하지 않다.
반드시 TensorFlow 설치 지시를 따랐는지 확인하라.
튜토리얼 파일
이 튜토리얼은 아래와 같은 파일들을 참조한다:
| 파일 | 목적 |
|---|---|
mnist.py |
이 코드는 완전히 연결된 MNIST 모델을 구축한다. |
fully_connected_feed.py |
메인 코드는 feed dictionary를 사용해 다운로드 한 데이터 셋에 대해 구축된 MNIST모델을 트레이닝 한다. |
트레이닝을 시작하기 위해 직접 fully_connected_feed.py 파일을 간단히 실행해 보라:
python fully_connected_feed.py
데이터 준비
MNIST는 머신 러닝에서 고전적인 문제다. 이 문제는 그레이 스케일(greyscale)인 손으로 쓴 숫자 28x28 픽셀 이미지를 보고 그 이미지가 표현하는 숫자가 0 부터 9 까지 숫자 중 어떤 것인지 판단하는 것이다.

더 많은 정보는 Yann LeCun's MNIST page 또는 Chris Olah's visualizations of MNIST 참고하라.
다운로드
run_training() 메소드의 맨 위에는, input_data.read_data_sets()
함수가 당신의 트레이닝 폴더에 올바른 데이터가 다운되었는지 확인하고,
DataSet 인스턴스의 딕셔너리에 반환하기 위해 그 데이터의 압축을 해제한다.
data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)
주의: fake_data flag 는 유닛 테스트의 목적으로 쓰이며 무시해도 이상이 없다.
| 데이터 셋 | 목적 |
|---|---|
data_sets.train |
기본 트레이닝을 위한 55000개의 이미지와 레이블. |
data_sets.validation |
트레이닝 정확도를 반복해서 검증하기 위한 5000개의 이미지와 레이블. |
data_sets.test |
트레이닝된 정확도를 마지막으로 테스트하기 위한 10000개의 이미지와 레이블. |
데이터에 대한 더 많은 정보는 Download tutorial을 읽어 보세요.
입력과 플레이스 홀더(Placeholders)
placeholder_inputs() 함수는 두개의 tf.placeholder ops를 생성한다.
이 ops는 batch_size 를 포함해, 남은 그래프를 위한 입력 형태와 실제 트레이닝 example의 입력 형태를 정의한다.
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))
트레이닝 반복 루프 더 아래 부분에서, 전체 이미지와 레이블 데이터셋이 각 순서에서 batch_size 에 맞게
나누어지고 이 플레이스 홀더 ops들과 매치된다. 그리고 나서 feed_dict 변수를 사용해 sess.run() 함수에 전달된다.
Build the Graph
데이터를 위한 플레이스 홀더를 생성한 후에, 3-스테이지 패턴(3-stage pattern):
inference(), loss(), training() 을 따라서 mnist.py 파일로부터 그래프가 생성됩니다.
inference()- 예측을 위해 network forward 실행에 필요한 수준의 그래프를 작성한다.loss()- inference 그래프에 loss를 생성하기 위해 필요한 ops를 더한다.training()- loss 그래프에 계산과 그라디언트(gradient)를 적용하기 위한 op를 더한다.
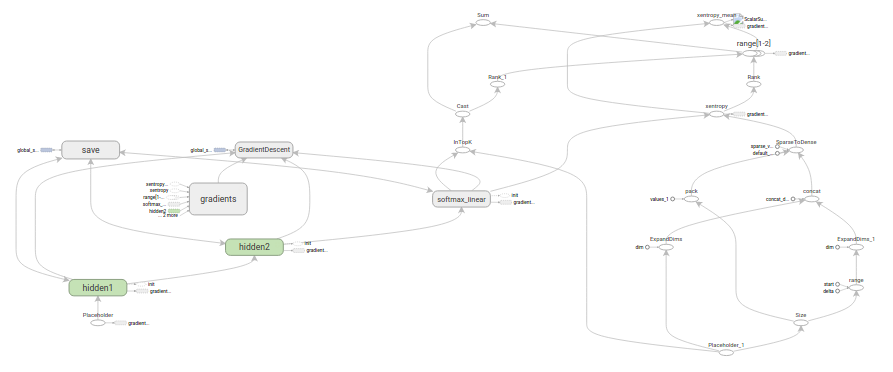
Inference
inference() 함수는 그래프를 작성하는데, 이 그래프는
예측한 출력을 가지는 tensor를 반환하는데 필요한 정도까지 작성된다.
이것은 이미지 플레이스 홀더를 입력으로 취하고 그 위에 출력 logits를 지정한 10 노드 선형 층(ten node linear layer)을 동반하는 ReLu) activation을 가진 한 쌍의 완전 연결 층(fully connected layer)을 만든다.
각 층은 고유한 tf.name_scope 아래에서 생성된다.
이것은 해당 범위(scope) 안에서 생성된 것에게 접두어와 같은 기능을 한다.
with tf.name_scope('hidden1'):
정의된 범위 내, weights와 biases의 층을 요구되는 형태로 tf.Variable
인스턴스 안에서 생성해 사용한다:
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases')
예를 들어, 이것들이 hidden1 범위 내에서 생성될 때는 weights 변수에 부여된 고유한 이름은
"hidden1/weights"다.
각 변수에게 initializer ops가 생성자(construction)의 일부로서 주어져 있다.
보통의 경우에, weights는 tf.truncated_normal로 초기화 되고
2-D tensor의 형태가 된다. 첫 번째 dim(차원. dimension)은 weights가 연결해 나온 층의 유닛(units) 갯수이고 두 번째 dim은
weights가 연결한 층의 유닛 갯수이다.
hidden1이라고 이름붙여진 첫 번째 레이어의 차원은 [IMAGE_PIXELS, hidden1_units] 다.
왜냐하면 weights가 이미지 입력과 hidden1 layer를 연결하고 있기 때문이다.
tf.truncated_normal initializer는 주어진 평균과 표준 편차를 가지고 임의의 분포를 생성한다.
그 후에 biases가 모두 0 값을 가지고 시작하도록 biases를
tf.zeros로 초기화한다.
그리고 그것의 형태는 단순히 연결된 층의 유닛 수가 된다.
그래프의 세가지 기본적인 ops -- 숨겨진 층(hidden layer) tf.matmul 을 감싸는
두개의 tf.nn.relu ops와
logits를 위한 추가 tf.matmul 하나 -- 가 분리된 tf.Variable 인스턴스와 함께 각각 차례대로 생성된다.
이 인스턴스는 각각의 입력 플레이스 홀더 또는 이전 레이어의 출력 tensor와 연결되어 있다.
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
logits = tf.matmul(hidden2, weights) + biases
마지막으로, 출력을 가질 logits tensor가 반환된다.
Loss
loss() 함수는 필요한 loss ops를 더해 그래프를 더 발전시킨다.
첫 번째로, labels_placeholder 에서 나온 값이 64비트 정수로 변환된다.
그 다음, tf.nn.sparse_softmax_cross_entropy_with_logits가
labels_placeholder에서 1-hot label을 자동으로 생성하고
inference() 함수의 1-hot labels 출력 logits을 비교하기 위해 추가된다.
labels = tf.to_int64(labels)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits, labels, name='xentropy')
그 후에 batch dimension(첫 번째 dimension)에 걸친 cross entropy 값을 총 손실(loss)로 구하기 위해
tf.reduce_mean를 사용한다.
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')
그리고 loss 값을 가질 tensor가 반환된다.
주의: Cross-entropy는 무엇이 정말 참인지를 고려해 볼 때, neural network의 예측을 믿는 것이 얼마나 나쁜지를 설명하게 해 준 정보 이론에서 가져온 아이디어다. 더 많은 정보는 Visual Information Theory 블로그 포스트를 읽어 보라 (http://colah.github.io/posts/2015-09-Visual-Information/)
Training
training() 함수는 Gradient Descent를 통해
손실을 최소화하기 위해 필요한 작업을 추가한다.
첫째로, loss() 함수로부터 loss tensor를 가지고 tf.scalar_summary에 넘겨준다.
tf.scalar_summary는 SummaryWriter와 쓰일 때 이벤트 파일에 요약 값(summary values)을
생성하는 op다. 이 경우에, 이것은 요약이 기록될 때 마다 손실 값의 스냅샷(snapshot)를 내보낸다.
tf.scalar_summary(loss.op.name, loss)
다음으로, 요청된 학습률에 gradients를 적용하는 tf.train.GradientDescentOptimizer
인스턴스를 생성한다.
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
그런 다음, 글로벌 트레이닝 단계(global training step)를 위한 카운터를 가진 변수 하나를 생성한다.
minimize() op는 시스템 내에서 트레이닝 가능한 weights와 글로벌 단계의 진행을 업데이트한다.
관례상, 이것은 train_op 로 알려져 있다. 그리고 이것은 트레이닝의 전체적인 단계를 진행하기 위해 반드시 TensorFlow session에서 실행되어야 한다.(아래 확인)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
트레이닝 op의 출력을 가진 tensor가 반환된다.
Train the Model
일단 그래프가 작성되면, 반복해서 트레이닝 할 수 있고 반복 루프(loop)에서 실행할 수 있습니다.
반복 루프(loop)는 fully_connected_feed.py 에 있는 유저 코드에 의해 컨트롤됩니다.
그래프
run_training() 함수의 상단에 python 명령어 with 이 있다.
이 명령어는 만들어진 모든 ops가 default global tf.Graph 인스턴스와 관련이 있음을 나타낸다.
with tf.Graph().as_default():
tf.Graph 는 그룹으로 합께 실행되는 ops의 모임이다.
대부분의 TensorFlow 사용은 오직 하나의 기본 그래프에 의존해야 한다.
다수의 그래프로 더 복잡한 사용이 가능하지만 이 간단한 튜토리얼의 범위에 벗어난다.
세션(Session)
만들 준비가 모두 완료되고 필요한 모든 ops가 생성되었다면, 그래프를 실행하기 위해
tf.Session을 만든다.
sess = tf.Session()
다른 방법으로, 범위 지정을 위한 with 블록에서 Session을 생성할 수 있다:
with tf.Session() as sess:
세션에 빈 파라미터는 이 코드가 기본 로컬 세션에 연결될 것임음(아직 로컬 세션이 생성되지 않았다면 생성할 것임)을 나타냅니다.
세션을 생성한 직후 tf.Variable의 초기화 op에서 sess.run()를 호출해
모든 tf.Variable 인스턴스가 초기화됩니다.
init = tf.initialize_all_variables()
sess.run(init)
sess.run() 메소드는
파라미터로 전달된 op(s)에 대응하는 그래프의 완벽한 부분집합을 실행합니다.
첫 번째 경우에, init op는 변수들의 initializer만을 가지고 있는 tf.group입니다.
그래프의 남은 부분 중 어떤 것도 여기서는 실행되지 않습니다. 그것은 아래의 트레이닝 반복 루프에서 일어납니다.
Train Loop
세션으로 변수들을 초기화 한 후, 트레이닝이 시작되었습니다.
사용자의 코드는 단계별로 트레이닝을 제어합니다. 쓸만한 트레이닝을 할 수 있는 간단한 루프:
for step in xrange(FLAGS.max_steps):
sess.run(train_op)
그러나 이 튜토리얼은 이전에 만든 플레이스 홀더에 맞게 각 단계에서 입력 데이터를 다듬어야 하기 때문에 약간 복잡하다.
Feed the Graph
각 단계에서, 코드는 이 단계를 위한 트레이닝 예시 셋을 포함하고 플레이스 홀더 ops가 키값이 되는 feed 딕셔너리를 생성한다.
fill_feed_dict() 함수에서, 주어진 DataSet은 다음 이미지와 레이블의 batch_size 셋을 검색한다.
그리고 다음 이미지와 레이블을 포함해 플레이스 홀더와 매칭된 tensors가 채워진다.
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size,
FLAGS.fake_data)
그러면 플레이스 홀더를 키 값으로하고 feed tensors를 value 값으로 해 python 딕셔너리 객체가 생성된다.
feed_dict = {
images_placeholder: images_feed,
labels_placeholder: labels_feed,
}
이것은 이 단계의 트레이닝에 대한 입력 예시를 제공하기 위해 sess.run() 함수의 feed_dict 파라미터로 전달된다.
Check the Status
이 코드는 실행 호출에서 가져오기 위해 두 값을 지정한다: [train_op, loss].
for step in xrange(FLAGS.max_steps):
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
_, loss_value = sess.run([train_op, loss],
feed_dict=feed_dict)
가져올 값이 두개기 때문에 sess.run()는 두개의 아이템을 가진 튜플을 반환한다.
가져올 값의 리스트에 있는 각 Tensor는 반환된 튜플에 있는 numpy 배열과 대응한다.
그리고 이 트레이닝 단계 동안 그 tensor의 값으로 채워진다.
train_op는 출력값이 없는 작업이기 때문에 반환된 튜플에서 대응하는 요소는 None이다. 그래서 버린다.
그러나 loss tensor의 값은 트레이닝 중에 모델이 나누어지면 NaN이 된다. 로그 기록을 위해 이 값을 캡쳐해 둔다.
트레이닝이 NaNs 없이 잘 실행되었다고 가정하면, 사용자가 트레이닝의 상태를 알게 하기 위해 트레이닝 루프가 매 100번째 단계마다 간단한 상태를 출력한다.
if step % 100 == 0:
print 'Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration)
상태 시각화
TensorBoard에서 사용된 이벤트 파일을 내보내기 위해서, 그래프 작성 단계에서 모든 요약자료를 (이 경우에는 하나) 하나의 op에 모아야 한다.
summary_op = tf.merge_all_summaries()
세션이 만들어진 후에, 그래프와 요약 값을 포함한 이벤트 파일을 작성하기 위해
tf.train.SummaryWriter 인스턴스가 생성되었을 것이다.
summary_writer = tf.train.SummaryWriter(FLAGS.train_dir, sess.graph)
마지막으로, 이벤트 파일은 summary_op가 실행되고 작성자의 add_summary() 함수에 출력이 전달될 때 마다
새로운 요약 값으로 업데이트 된다.
summary_str = sess.run(summary_op, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)
이벤트 파일이 쓰여지면, 요약 값들을 보여주기 위해 TensorBoard가 트레이닝 폴더에 대해 실행될 것이다.

주의: 어떻게 Tensorboard를 만들고 실행하는지에 대한 더 많은 정보는, 동봉된 튜토리얼을 보시기 바랍니다. Tensorboard: 학습을 시각화하기.
Save a Checkpoint
나중에 추가적인 트레이닝이나 평가를 위해 모델을 복구하는데 쓰일 수 있는 checkpoint 파일을 내보내기 위해서,
tf.train.Saver 인스턴트를 생성합니다.
saver = tf.train.Saver()
트레이닝 루프에서, 모든 트레이닝 할 수 있는 변수들의 현재 값을 트레이닝 디렉토리에 있는 checkpoint 파일에 쓰기 위해
saver.save() 메소드를 정기적으로 호출한다.
saver.save(sess, FLAGS.train_dir, global_step=step)
미래에 나중에 생성된 몇개의 포인터에서, 모델 파라미터를 불러오기 위해 saver.restore()
메소드를 사용해 트레이닝을 재개할 수도 있다.
saver.restore(sess, FLAGS.train_dir)
Evaluate the Model
매 1000번째 단계마다, 코드는 트레이닝과 테스트 데이터셋에 대해 모델 평가를 시도한다.
Training, validation, test dataset 을 위해 do_eval() 함수를 세 번 호출한다.
print 'Training Data Eval:'
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
print 'Validation Data Eval:'
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
print 'Test Data Eval:'
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test)
더 복잡한 데이터를 다룰 때는 일반적으로 매우 많은 양의 hyperparameter를 조절한 후,
data_sets.test만 체크한다. 그러나 간단한 MNIST 문제에 대해서는 모든 데이터에 대해 확인한다.
Build the Eval Graph
트레이닝 루프에 들어가기 전에, loss() 함수와 같은 logits/labels 파라미터로
mnist.py에서 evaluation() 함수를 호출해 Eval op를 생성했어야 한다.
eval_correct = mnist.evaluation(logits, labels_placeholder)
evaluation() 함수는 단순히 tf.nn.in_top_kop를 생성한다.
이 op는 자동적으로 참인 레이블이 K most-likely 예측에서 발견되면, 각 모델의 출력을 올바르다고 채점한다.
이 경우에 참인 레이블에 대해 예측이 옳았을 경우만 K의 값을 1로 설정합니다.
eval_correct = tf.nn.in_top_k(logits, labels, 1)
Eval Output
feed_dict를 채우기 위해 루프를 만들수 있고 eval_correct op에 대해 sess.run()를
호출해서 주어진 테이터셋의 모델을 평가할 수 있습니다.
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set,
images_placeholder,
labels_placeholder)
true_count += sess.run(eval_correct, feed_dict=feed_dict)
true_count 변수는 간단히 in_top_k op가 옳다고 판단한 모든 예측들을 축적합니다.
그것을 간단히 예시의 총 갯수로 나누어 정확도를 계산합니다.
precision = true_count / num_examples
print(' Num examples: %d Num correct: %d Precision @ 1: %0.04f' %
(num_examples, true_count, precision))