단어들의 벡터 표현
(v1.0)
이 튜토리얼에서 Mikolov et al. 의 word2vec 모델을 살펴본다. 이 모델은 "word embeddings" 라 불리는 단어들의 벡터 표현 학습에 사용된다.
강조점(Highlights)
이 튜토리얼은 TensorFlow 에서 word2vec 모델을 만드는 흥미롭고 실질적인 부분들을 강조할 예정이다.
- 왜 단어들을 벡터들로 표현해야 하는지에 대한 동기부여를 주는 것에서 시작한다.
- 모델 넘어의 직관력과 이것이 어떻게 학습되어지는지(정확한 측정을 위한 수학 사용과 함께) 알아본다.
- 또한 TensorFlow 에서 모델의 간단한 구현을 보인다.
- 마지막으로, 초기 버전 수준을 더 잘 만들수 있는 방법을 알아본다.
이후에 튜토리얼에서는 코드를 보여줄 것이나, 좀 더 자세히 알고 싶다면 tensorflow/examples/tutorials/word2vec/word2vec_basic.py 의 최소화된 구현을 참고하자. 이 기본 예제는 특정 데이터를 다운로드 하기 위해 필요한 코드, 이것을 약간 학습하기 위한 코드, 그리고 결과를 시각화하기 위하 코드를 포함한다. 기본 버전을 읽고 실행하는데 익숙해지면, 쓰레드를 이용하여 어떻게 효율적으로 데이터를 텍스트 모델로 이동시키는지, 학습하는 동안 어떻게 체크하는지 등에 대한 좀 더 심화된 TensorFlow 원리들을 보여주는 심화 구현된 tensorflow_models/tutorials/embedding/word2vec.py 을 시작할 수 있다.
하지만 우선, 전반부에 왜 word embeddings 를 배워야 하는지 살펴보자. 자신이 Embedding 을 잘 알고 자세한 설명들이 혼란스럽다고 생각하면 이 부분을 넘어가도 된다.
동기부여 : 왜 Word Embeddings 를 배워야하지?
이미지, 오디오 처리 시스템들은 이미지 데이터에 대하여 개별의 가공되지 않은 픽셀-강도값의 벡터들이나 오디오 데이터에 대한 파워스펙트럴밀도계수로 기록된 대량, 고차원 dataset 들과 함께 한다. 객체나 연설 인식과 같은 문제에서 문제를 성공적으로 수행하기 위해 필요한 모든 정보는 데이터로 저장된다는 것을 알고있다(사람은 이러한 문제를 가공되지 않은 데이터로부터 수행하기 때문이다). 그러나 자연어 처리 시스템들은 일반적으로 이산 원자 기호들(discrete atomic symbols)의 단어들로 다룬다. 따라서 'cat' 은 'Id537'로, 'dog' 은 'Id143'로 표현될 수 있다. 이 저장된 것들은 임의적이며, 개별 심볼들(symbols) 간에 존재하는 관계에 관해 시스템과는 의미없는 정보를 제공한다. 이것은 'dogs' 라는 처리 데이터일 때 'cats' 을 배우는 것이 영향력이 매우 적음을 의미한다.(이들 모두 동물, 네 다리, 애완동물, 등) 유일하고 이산의(discrete) id 들로 단어들을 표현하는 것은 데이터를 더욱 드문드문(sparsity) 하게 만들고, 대체적으로 통계적 모델들을 성공적으로 학습하기 위해 더 많은 데이터가 필요함을 의미한다. 벡터 표현들을 사용하는 것은 다음과 같은 장애들을 해결할 수 있다.

벡터공간 모델(Vector space models) (VSMs) 은 의미상 유사한 단어들은 가까운 지점으로 매핑되어지는(서로 가깝게 의미하는) 연속된 벡터 공간의 단어들로 표현(내포)한다. VSMs 은 NLP 에서 오래되고 깊은 역사를 가지고 있지만, 모든 방법들은 Distributional Hypothesis 의 특정 방법이나 다른 방법에 따른다. 그리고 이 논문은 같은 맥락에서 나타나는 단어들은 시멘틱(semantic) 의미를 공유한다고 설명한다. 이 원리에 영향을 주는 다른 접근법들은 두 범주로 나눠진다: count-based methods (e.g.Latent Semantic Analysis) 와 predictive methods (e.g.neural probabilistic language models).
이 차이는 Baroni et al. 에 의해 더 자세하게 설명되어 있다. 간략하게 말해: Count-based methods 는 큰 텍스트 말뭉치에서 특정 단어가 그 주변 단어들과 함께 얼마나 자주 나타나는지에 대한 통계를 계산한다, 그리고 이 count-statistics 를 각각의 단어에 대해 작고 dense 벡터로 상세히 묘사한다. 예측 모델(Predictive models) 은 학습된 작고, dense embedding vectors (모델의 파라미터들로 고려된) 에 관해 직접적으로 단어를 그 주변 단어들로부터 예측하려 한다.
Word2vec 는 특히 가공하지 않은 텍스트로부터 학습한 단어 embeddings 에 대해 계산적으로 효율적인 예측 모델이다. 이는 두 가지 종류로 나타난다, Continuous Bag-of-Word(CBOW) 모델과 Skip-Gram 모델(Mikolov et al. 의 Chapter 3.1과 3.2). 알고리즘적으로, 이들 모델들은 CBOW 는 원본 컨텍스트 단어들('the cat sits on the') 로부터 타켓 단어들(e.g. 'mat') 을 예측하는 반면 skip-gram 은 타겟 단어들로부터 원본 컨텍스트 단어들을 역으로 예측한다는 점을 제외하고 유사하다. 이 정반대는 임의적인 선택인 것 처럼 보이지만, 통계적으로 CBOW 는 많은 수의 분포상 정보를 바로잡는 효과를 가진다(전체 컨텍스트를 하나의 관찰로 처리함으로써). 대부분의 경우, 이러한 점은 작은 datasets 일 수록 유용한 것으로 밝혀졌다. 하지만 skip-gram 은 각 컨텍스트-타겟 쌍을 새로운 발견으로 처리하고, 이것은 큰 규모의 datasets 을 가질 때 더 잘 동작하는 경향이 있다. 이 튜토리얼의 나머지는 skip-gram 모델에 초점을 맞출 것이다.
Noise-Contrastive 학습을 이용한 규모확장
신경 확률 언어 모델들(Neural probabilistic language models) 은 일반적으로 softmax function 에 대해 이전에 주어진 단어들 \(h\) (for "history") 에서 다음 단어(\(w_t\)(for "target") 에 대한 확률을 최대화하는 maximum likelihood (ML) 원리를 이용하여 학습되어 진다.
\(\text{score}(w_t, h)\) 은 컨텍스트와 함께 하는 단어의 호환성을 계산한다(일반적으로 내적이 사용된다). 우리는 학습하는 set 에서 이것의 log-likelihood 를 최대화 함으로써 모델을 학습한다. 즉 최대화 하도록.
이것은 언어 모델링에 대해서 적절하게 정규화된 확률 모델을 만들어 낸다. 하지만 이 방법은, 매 학습 스텝(at every training step), 현재 컨텍스트 \(h\) 에서 다른 모든\(V\) words \(w'\) 에 대한 범위를 이용한 각 확률을 계산하고 정규화하는 것이 필요하기 때문에 그 비용이 매우 비싸다.

반면, word2vec 의 feature 학습에 대하여 완전 확률 모델(a full probabilistic model) 을 필요로 하지 않는다. 대신 CBOW 와 skip-gram 모델은, 같은 컨텍스트 내에서, 실제 타겟 단어들 \(w_t\) 을 가상(노이즈) 단어들 \(\tilde w\) 로부터 구별해 내기 위한 이진 분류 목적함수 (logistic regression) 를 이용하여 학습되어 진다. CBOW 모델에 대한 것은 아래에 도식화하였다. skip-gram 에 대해 방향이 단순히 반대로 되어 있다.
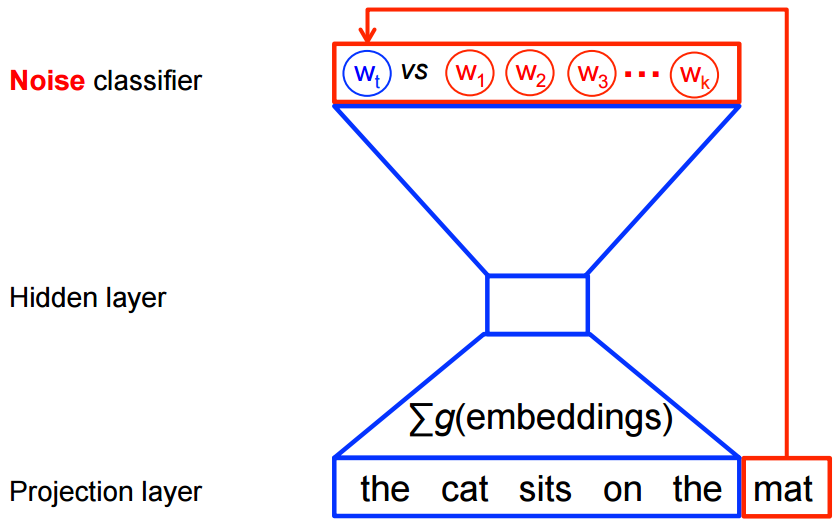
수학적으로, 목적함수(각 예제에 대해) 는 이를 최대화 한다.
\(Q_\theta(D=1 | w, h)\) 은 학습된 embedding vectors \(\theta\) 에 대해 계산된 dataset\(D\) 내 컨텍스트\(h\) 에서 보여지는 단어 (\(w\) 의 모델에 대해서 이진 로지스틱 회귀 확률인 조건이다. 실제로 노이즈 분포로부터 대조되는 단어는 찾아냄으로써 기대값을 가늠한다 (즉, Monte Carlo average 를 계산한다).
이 목적함수는 모델이 실제 단어들에 높은 확률을 할당하고 노이즈 단어들에 낮은 확률을 할당할 때 최대화된다. 기술적으로, 이를 Negative Sampling 이라 명하며, 이 손실(loss) 함수 사용에 대해 수학적으로 유리한 동기가 존재한다: 제시되는 업데이트들은 제한된 softmax 함수의 업데이트들을 근사값을 계산한다. 하지만 손실 함수의 계산을 우리가 선택한 noise words(\(k\)) 의 갯수, 어휘(\(V\)) 내 모든 단어(all words) 가 아닌, 만으로 변경하여 계산한다는 점 때문에 계산적으로 특히 매력적이다. 이것은 학습을 더욱 빠르게 만든다. 우리는 noise-contrastive estimation (NCE) 손실(loss) 와 매우 유사한 것, TensorFlow 가 가지고 있는 유용한 헬퍼 함수 tf.nn.nce_loss(), 를 활용할 것이다.
이제 실제로 어떻게 동작하는지에 직관적으로 이해해보자.
Skip-gram 모델
예제로, dataset 을 생각해보자
the quick brown fox jumped over the lazy dog
우선 단어들과 컨택스트들 자신들이 존재하는 dataset 을 만든다. 우리는 여러 타당한 방법으로 'context' 를 정의할 수 있고, 사실 사람들은 타겟의 좌측 단어, 타겟의 우측 단어 등을 통해 통사적 문맥(즉, 현재 타겟 단어의 통사적 의존성, 참고 Levy et al.) 을 살펴보게 된다. 이제부터, 평범한 정의와 연관지어보고 타겟 단어의 좌측과 우측의 단어들의 윈도우로 'context' 를 정의해보자. 크기 1 의 윈도우를 이용하면, (context, target) 쌍의 dataset 을 가지게 된다.
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), ...
skip-gram 은 컨텍스트들과 타겟들의 관계를 도치하고, 이들 타겟 단어로부터 각 컨텍스트 단어의 예측을 시도한다는 점을 상기하자. 그래서 문제는 'quick' 으로부터 'the' 와 'brown' 을, 'brown' 으로부터 'quick' 과 'fox' 등을 예측하는 것이 된다. 따라서 우리의 dataset 은 (input, output) 쌍의 dataset 이 된다.
(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
목적함수는 전체 dataset 에 대해 정의 되지만, 일반적으로 한번에 한 예를 이용한 stochastic gradient descent(SGD) 로 목적함수를 최적화 한다(또는 일반적으로 16 <= batch_size <= 512 인 batch_size 예제들의 'minibatch'). 그럼 이 과정의 한 단계를 살펴보자.
quick 에서 the 를 예측하는 것이 목표인 조건에서 우리가 관찰한 위 첫 학습 케이스의 학습 단계\(t\) 를 상상해보자. 우리는 특정 노이즈 분포, 일반적으로 unigram 분포 \(P(w)\), 로부터 이끌어 낸 noisy (contrastive) 예제들의 num_noise 값을 선택했다. 간단하게, noisy 예제에서 num_noise=1 이라하고, sheep 을 선택한다. 이어서 이 관찰된 쌍과 noisy 예제들의 loss 를 계산한다, 즉 time step \(t\) 에서 목적함수는 아래와 같이 된다.
목표는 이 목적 함수를 향상시키기 위한(여기서는 최대화) embedding parameters \(\theta\) 를 업데이트 시키는 것이다. 이는 embedding parameters \(\theta\) 에 대해서 loss 의 gradient 를 미분함으로써 수행한다, 즉 \(\frac{\partial}{\partial \theta} J_\text{NEG}\) (다행히 TensorFlow 는 이를 위해 쉬운 헬퍼 함수들을 제공한다!). 다음으로 gradient 방향으로 조금 진행하여 얻은 embeddings 의 업데이트를 수행한다. 전체 학습 set 에 걸처 이 과정을 반복할 때, 모델이 실제 단어들를 노이즈 단어들로부터 구별하는 것을 성공적으로 할 때까지 각 단어들에 대한 embedding 벡터들을 'moving' 하는 효과를 가진다.
예를 들어 t-SNE dimensionality reduction technique 와 같은 이용으로 학습된 벡터들을 2차원으로 투영하여 이들을 시각화 할 수 있다. 이들 시각화된 정보들을 살펴보면, 벡터들이 단어들과 그들과 다른 나머지들과의 관계에 대한 일반적이고, 사실 꽤 유용하고, 시멘틱(의미론적인, semantic) 정보를 담는다는 것을 분명히 할 수 있다. 유도된 벡터 공간에서의 특정 방향성은 특정 시멘틱 관계로 특징화되어 연결된다는 우리의 첫 발견은 매우 흥미로웠다, 즉 male-femal, gender, 그리고 심지어 country-capital 단어들 간의 관계, 아래 그림에 도식화하였다(예제 참고, Mikolov et al., 2013).
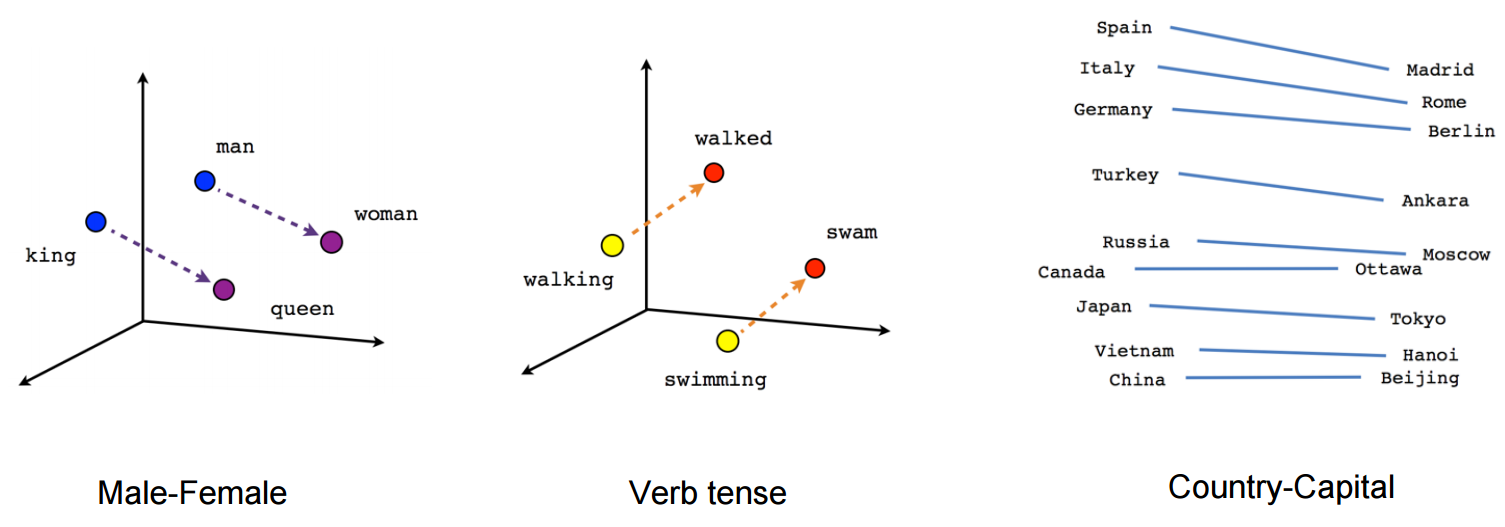
이것은 품사(part-of-speech) tagging 이나 개체명 인식과 같은 여러 고전 NLP 예측 문제들에 대해 이들 벡터들이 왜 유용한 features 인지 설명한다(원저작물인 Collobert et al., 2011(pdf) 예제를 참고하거나 후속 연구인 Turian et al., 2010 을 참고하자).
이제 이들을 이용해서 멋진 그림들을 그려보자!
Graph 구성하기
이것은 embeddings 에 대한 모든 것이다. 그럼 우리의 embedding 매트릭스를 정의해보자. 이것은 시작하기 위한 랜덤 매트릭스일 뿐이다. 우리는 이 유닛 큐브의 값이 균일하도록 초기화 할 것이다.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
noise-contrastive estimation loss 는 로지스틱 회귀 모델에 관하여 정의 되어진다. 이를 위해, 어휘(vocabulary) 의 각 단어에 대한 가중치(weights)와 편향(biases) 을 정의할 필요가 있다(input embeddings 와 대조되어 output weights 라 불린다). 그럼 정의해보자.
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
파라미터들이 준비되었고, 이제 우리의 skip-gram 모델 그래프를 정의할 수 있다. 간단하게, 우리의 텍스트 말뭉치(corpus) 를 어휘(vocabulary)로 미리 정수화했다 가정하자. 그럼 각 단어는 정수로 표현되어 진다(자세한 사항은 다음을 참고하자, tensorflow/examples/tutorials/word2vec/word2vec_basic.py). skip-gram 모델은 두 입력을 가진다. 하나는 원본 컨텍스트 단어들을 대표하는 정수들의 집합이고, 다른 하나는 타겟 단어들이다. 이들 입력들에 대한 placeholder 노드들을 만들어 보자. 그래야 나중에 데이터를 입력할 수 있다.
# Placeholders for inputs
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
이제 필요한 것은 집단(batch) 안의 각 원본 단어들에 대한 벡터를 살펴보는 것이다. TensorFlow 는 이를 쉽게 해주는 편리한 헬퍼들을 가지고 있다.
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
좋다, 이제 각 단어에 대한 embeddings 을 만들었고, noise-contrastive 학습 목적함수를 이용한 타겟 단어 예측을 시도를 해보자.
# 매번 음수 라벨링 된 셈플을 이용한 NCE loss 계산
loss = tf.reduce_mean(
tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels,
num_sampled, vocabulary_size))
loss 노드를 만들었고, 이제 gradients 를 계산하고 파라미터들을 업데이트 하는 등에 필요한 노드들을 추가할 필요가 있다. 이를 위해 stochastic gradient descent 를 사용할 것이다. 그리고 TensorFlow 는 이를 매우 쉽게 만들어주는 편리한 헬퍼들을 가지고 있다.
# SGD optimizer 를 사용
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
모델 학습하기
모델을 학습하는 것은 데이터를 placeholders 에 넣기 위해 feed_dict 를 사용하는 것 만큼 간단하며 루프 내에서 새로운 데이터와 함께 session.run 를 불러 함수를 사용할 수 있다.
for inputs, labels in generate_batch(...):
feed_dict = {training_inputs: inputs, training_labels: labels}
_, cur_loss = session.run([optimizer, loss], feed_dict=feed_dict)
전체 예제 코드는 tensorflow/examples/tutorials/word2vec/word2vec_basic.py 을 살펴보자.
학습한 Embeddings 시각화하기
학습이 완료된 후 t-SNE 를 사용하여 학습한 embeddings 를 시각화 할 수 있다.
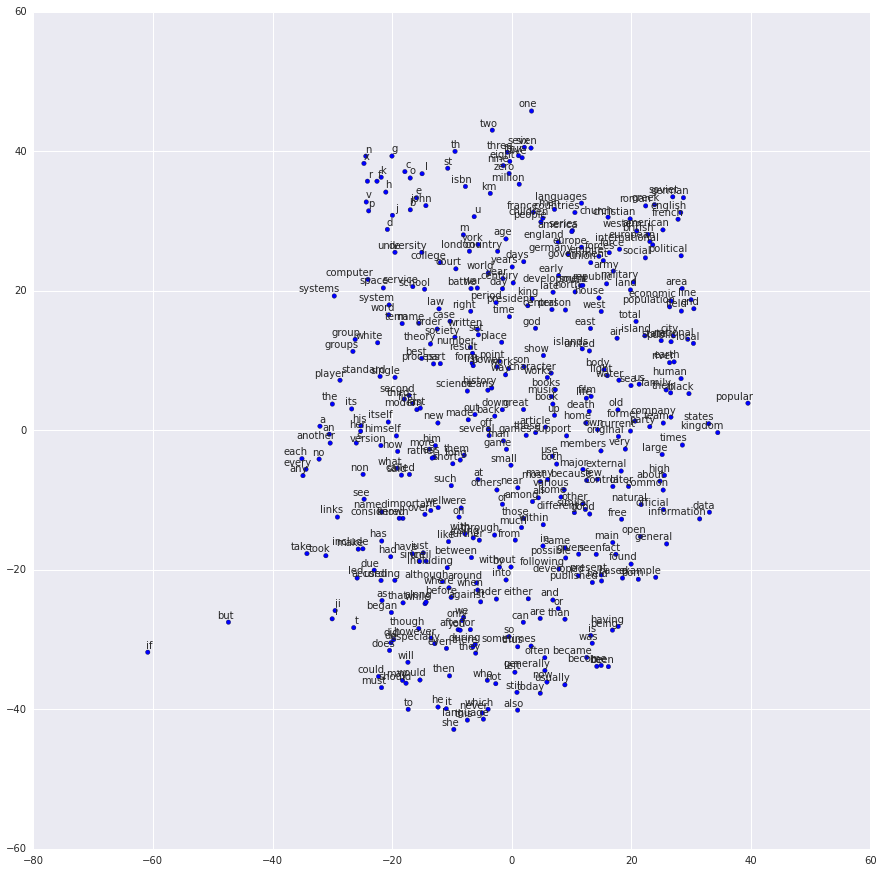
이제 다 됐어! 예상한 것 처럼 비슷한 단어들은 결국 서로 가까운 집단화(clustering) 된다. TensorFlow 의 더욱 진보된 features 를 보여주는 비중있는 word2vec 구현을 위해서, tensorflow_models/tutorials/embedding/word2vec.py 을 참고하자.
Embeddings 평가하기 : 유추(Analogical Reasoning)
Embeddings 는 NLP 의 다양한 예측 문제에 대해 유용하다. 완전 품사 모델이나 개체명 모델의 학습을 제외하고, embeddings 를 평가하는 한가지 간단한 방법은 이들을 직접 사용하여 king is to queen as father is to ? 와 같이 구문론적인 그리고 의미론적인 관계를 예측하는 것이다. 이 방법을 유추(analogical reasoning) 이라고 부르며 Mikolov and colleagues 에 의해 소개되었고, dataset 은 여기에서 다운로드 할 수 있다: https://word2vec.googlecode.com/svn/trunk/questions-words.txt.
어떻게 이 평가를 수행하는 알기 위해선, tensorflow_models/tutorials/embedding/word2vec.py 의 build_eval_graph() 와 eval() 함수를 살펴봐라.
hyperparameters 의 선정은 이 문제의 정확도에 매우 큰 영향을 줄 수 있다. 이 문제에 대해 최고의 성과를 달성하기 위해선 매우 큰 dataset 을 학습하는 것, hyperparameters 에 대한 신중한 조절, 그리고 데이터의 이단추출과 같은 기법을 이용하는 것이 필요하다. 그리고 이 기법들은 이 튜토리얼의 범위를 넘어가는 것이다.
구현 최적화하기
우리의 평범한 구현은 TensorFlow 이 다루기 쉬움을의 보여준다. 예를들어 학습 목적함수의 변화는 tf.nn.nce_loss() 을 tf.nn.sampled_softmax_loss() 와 같은 대체 함수로 교체하는 것 만큼 간단하다. loss 함수에 대해 새로운 아이디어가 있다면, TensorFlow 내에서 새로운 목적함수에 대해 직접 고쳐 표현할 수 있으며 최적화 도구로 이것의 미분을 계산할 수 있다. 여러 다른 아이디어를 시도하거나 빠르게 반복할 경우, 이러한 용이성은 머신 러닝 모델 개발의 탐색 단계에서 매우 가치가 있다.
만족할 만한 모델 구조를 가지고 있다면, 당신의 구현을 더 효율적으로 실행하기 위해(그리고 적은 시간에 더 많은 데이터를 다룰수 있게 하기 위해) 최적화할 가치가 있을 수 있다. 예를 들어, 우리가 이 튜토리얼에서 사용한 간단한 코드는 데이터 아이템들을 읽고 대입하는데 --이들 각각은 TensorFlow back-end 에서 매우 적게 고려된다-- Python 을 사용하기 때문에 절충된 속도로 수행된다. 만일 당신의 모델이 입력 데이터에 대해 심각한 병목현상을 격는 것을 발견한다면, New Data Formats 에 설명된 것과 처럼, 수정된 데이터 리더(reader) 를 구현할 수 있을 것이다. Skip-gram 모델링의 경우, tensorflow_models/tutorials/embedding/word2vec.py 의 예제와 같이 이미 다루었다.
당신의 모델이 입출력 바운드 뿐만아니라 더 높은 성능을 원한다면, Adding a New Op 에 설명된 것처럼, 당신의 TensorFlow Ops 작성을 통해 자세한 설명을 할 수 있다. 이것에 대한 Skip-Gram 예제는 tensorflow_models/tutorials/embedding/word2vec_optimized.py 에 제시했다. 각 단계의 성능 향상 측정을 위해 각각에 대해 자유롭게 벤치마크 해보자.
결론
이 튜토리얼에서 word embeddings 학습에 대해 계산적으로 효율적인 모델인, word2vec 모델을 다뤘다. 우리는 왜 embeddings 가 유용한지 동기부여를 했고, 효율적인 학습 기술들에 대한 논의했으며, TensorFlow 에서 이 모든 것들을 어떻게 구현하는지 보였다. 종합하면, 이것들은 어떻게 TensorFlow 가 초기 실험에 필요한 용이성을 제공하고, 나중에 개인 맞춤의 최적화된 구현에 필요한 조작을 하는지 보여주기를 바란다.